event sourcing and why it's perfect for agents
the first thing i noticed once i started working with llm's was that a lot of this new probabilistic infra has deterministic counterparts we've known for decades.
- SQL and vector databases -> both store rows we query later (one with SQL queries and the other with cosine similarity)
- cache and context window -> cache is a bounded fast memory sitting in front of a slower storage and context is a bounded fast memory in front of model weights. in both places it's our job to prioritise what's worth keeping warm and handy.
- RAG is just lossy and probabilistic denormalisation.
- tool calls are stored procedures. named, parameterised, side-effecting, results come back as data.
all we have been doing is reinventing plumbing because the pipes are carrying something weirder.
now the mirror i'm interested in talking about here is event-sourcing. this was my whole motivation behind building starling, which started as a proof of concept and has now turned into something very very real.
this post is about why event sourcing is the right shape for agents and some of the cool stuff i had to take care of while building it.
what's event sourcing
if you've worked with WALs and databases, you've already seen it. instead of storing the current state of something, you store the sequence of events that produced it. this sequence must be append-only and immutable.
now to get the current state, you just run the sequence of stored operations on the initial state.
this trick buys us four moves:
- the past is queryable
- we can travel through time
- we can audit the current state through history
- we can reproduce state anywhere
ok but why apply it to agents
it's very obvious if we think about it.
agents are deterministic code wrapped around non-deterministic decisions. most agents built today follow some skewed version of the ReAct loop which is just reasoning, acting or tool calling, observing, and repeating. the reason step is the model deciding what it should do, the act step is our code dispatching the chosen tool and the observe step is the tool's response coming back from the world.
we have three layers working together and three moving parts where anything could go wrong, so when something does go wrong eventually, it's not an easy job to tell what by looking at the final state.
hold up now, we already log everything so what's event sourcing gonna do?
if you've worked with raft before(or read about it if you haven't), you know that its whole thesis is that the log is the system.
state is a function of the log. replication is replicating the log. crash recovery is replaying the log.
the log gives us a guarantee and confidence that wouldn't be there otherwise. the log is actually useful to us and we build things on top of raft because of these guarantees.
event sourcing for agents is the same move.
the events are the substrate. and that's what unlocks the things logs can't give you. you can write a function that replays a recorded run through current code because the events are guaranteed complete and the bytes are guaranteed stable. you can write a function that proves a run wasn't tampered with because events form a hash chain. you can write a function that resumes a crashed run because every state the agent passed through is in the log. you can do cross-run analysis, find every time the model retried more than it should have or every run that hit budget, or every place the same tool returned the same error. these aren't features you bolt on. they're consequences of the system making guarantees.
(all of this is possible in starling btw)
what an event looks like in starling
here's what an event looks like in starling. (real run in starling-inspect, 9 events, 2 turns, 1 tool call)
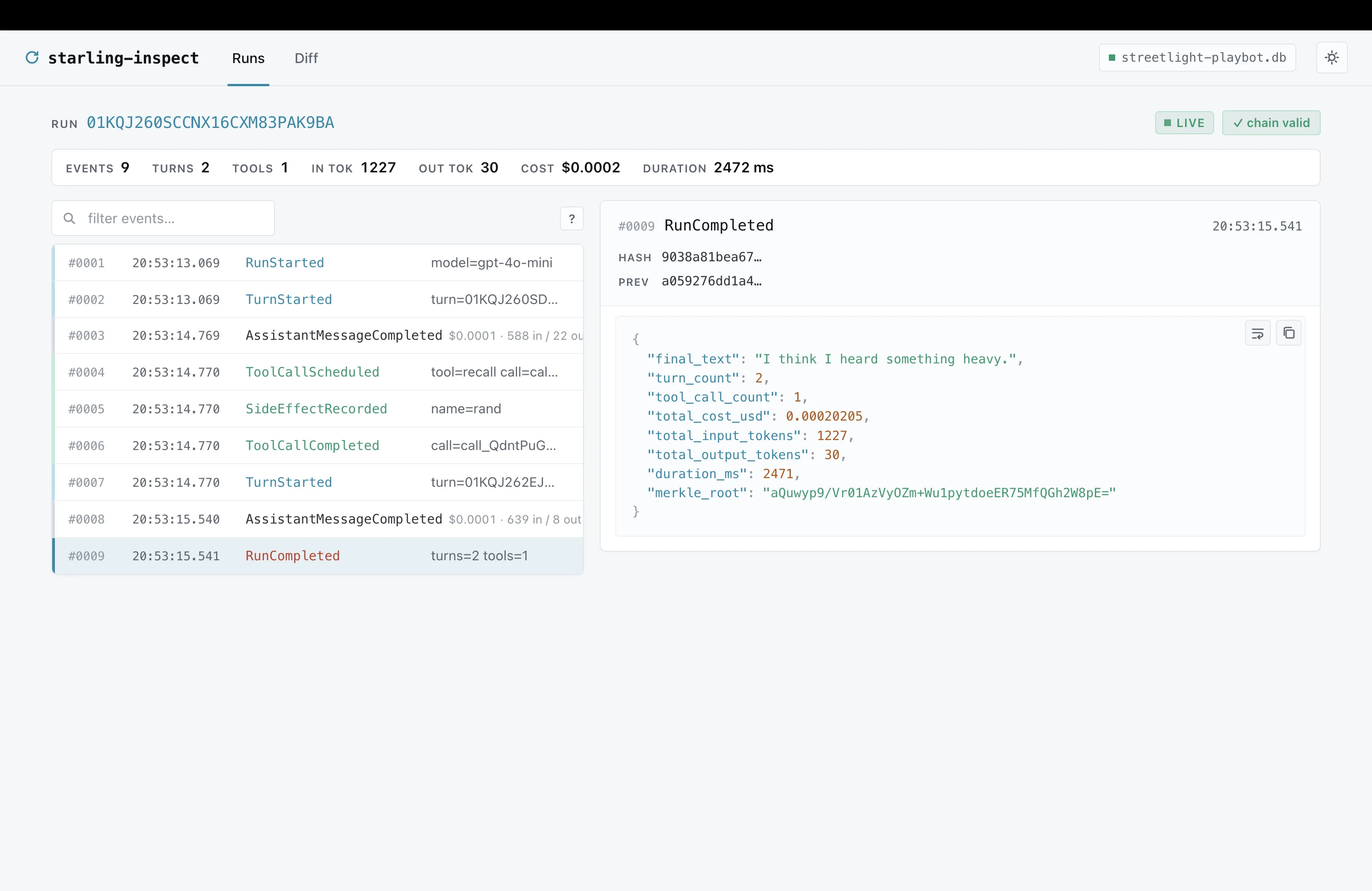
read the event list top to bottom. you can follow what happened without seeing any code:
RunStartedrecords the model,gpt-4o-minihere.TurnStartedopens turn 1.AssistantMessageCompletedis the model speaking. 588 input tokens, 22 output, costs $0.0001.- the model decided to call a tool, so
ToolCallScheduledfires. - the tool used some randomness, captured as
SideEffectRecorded name=rand(more on this in a sec.) - the tool returned (
ToolCallCompleted). - turn 2 opens, model speaks again, run completes.
starling has fifteen event kinds total.
goconst ( KindRunStarted Kind = 1 KindUserMessageAppended Kind = 2 KindTurnStarted Kind = 3 KindReasoningEmitted Kind = 4 KindAssistantMessageCompleted Kind = 5 KindToolCallScheduled Kind = 6 KindToolCallCompleted Kind = 7 KindToolCallFailed Kind = 8 KindSideEffectRecorded Kind = 9 KindBudgetExceeded Kind = 10 KindContextTruncated Kind = 11 KindRunCompleted Kind = 12 KindRunFailed Kind = 13 KindRunCancelled Kind = 14 KindRunResumed Kind = 15 )
someone who hasn't even worked with agents in the past can now tell what's going on here at a glance.
what makes starling work (some cryptography stuff)
once i committed to these events being the source of truth, a couple of problems popped up.
p1: encoding has to be deterministic since we're storing events as structs, we have to encode them and JSON couldn't cut it since we can't afford to let two events with identical fields serialise differently.
here's why this matters, the next two layers (the hash chain and merkle root) both work by hashing event bytes. the same data has to produce the same bytes otherwise we end up with hashes that don't match for reasons that have nothing to do with tampering.
so starling uses canonical CBOR (RFC 8949) which is like "JSON but designed for machines instead of humans" and the canonical part just means for the same data we'll always get the same bytes.
p2: anyone with write access can rewrite history since the events live in a database (psql or sqlite), the application layer has write access to it cause that's how the events get appended obviously. there are quite a lot of way to intentionally or accidentally rewrite history in such cases, some common ones being compromised credentials, migrations, some dumb quick fix by the future you, idk.
we can't prevent event tampering but we can make it visible and impossible to hide.
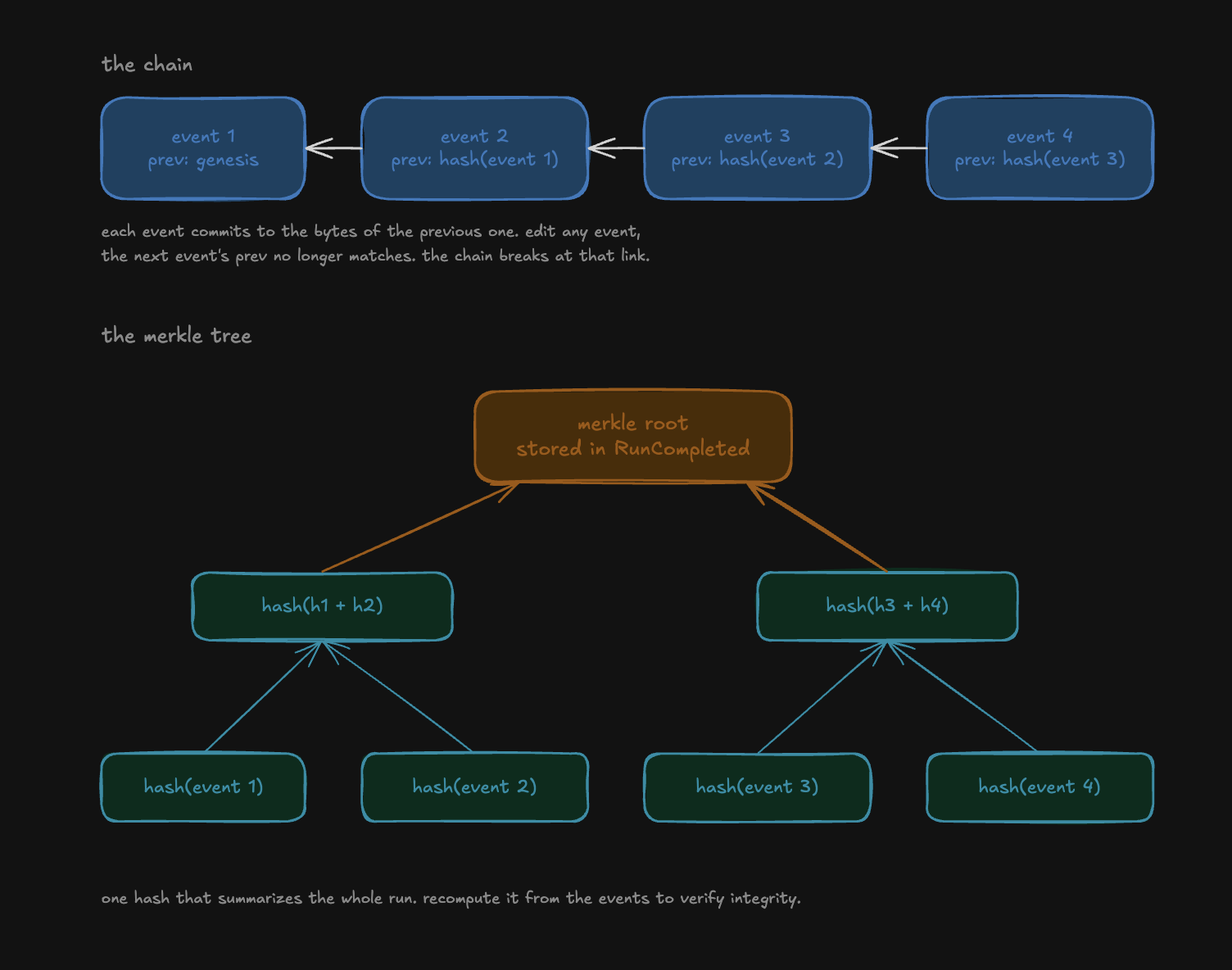
each event in starling records prev = hash(canonical CBOR of the previous event). the hash is BLAKE3, super fast since we're gonna be hashing every event. that's the prev field in the detail panel. event 2 stores a fingerprint of event 1, event 3 stores a fingerprint of event 2, all the way through. mutate any prior event and the hash you'd compute for it now is different from the prev recorded in the next event. the chain breaks at the exact point of tampering and you can see where.
p3: walking the chain every time is slow
the chain works, but verifying a run with it means walking every event in order and recomputing prev. the problem is obvious, we need to recompute hundreds of thousands of hashes every time someone wants to check the recording is intact.
what's even worse is that you can't share the verification without sending someone the entire log so they can walk it themselves.
so the terminal event commits a merkle root. (a single hash that captures the entire run (you must be familiar with this if you have ever dealt with blockchains))
here's how it works, we already have hashes of all the events, we take them in pairs and calculate new hashes, we take those pairs in pairs again and repeat until we're finally left with one hash.
every event's hash is folded into that final value. change any single byte in any single event, and its hash changes, and that change propagates up the tree to the root. the root is now different. you can't edit anything without the root noticing.
starling stores this root in whichever terminal event ends the run, RunCompleted, RunFailed, or RunCancelled. crashed and cancelled runs are tamper-evident too. you can hand this one value to anyone and they can recompute it from the events themselves. match means the run is intact and mismatch means it was edited somewhere.
why are we saving agent logs like it's a private key?
i think people are gonna be handing agents decisions that matter. loans, medical triage, legal docs, therapy. and the version of "we logged it and it's okay" that exists today is not good enough.
building this critical infra on a steady foundation now matters more than hacking together a fix later.
also this is my project and i just wanted to.
replays (absurdly overengineered and completely worth it)
alright, here's the cool thing. since events are the source of truth now, we get to do something really cool.
you can now take today's code and run it through yesterday's recorded run and see what changed
starling replay is not "re-run the prompt against the model." that's regression testing on inputs, the model is non-deterministic, you'll always get a different answer, you've learned nothing about whether your code changed behaviour.
it's not "resume from a checkpoint and continue." either, that's durable execution. resume re-invokes the model. you get fresh non-deterministic output sitting in the middle of your reproduction attempt.
what i'm talking about is taking the recorded events, feeding them back through today's agent loop, and watching whether today's code regenerates the same events in the same order with the same bytes.
the model is never called. recorded values get fed back in place of every non-deterministic thing, AssistantMessageCompleted, ToolCallCompleted, every captured time.Now() or rand. the only thing varying between the recording and the replay is your code.
if it diverges, you get the seq number of the first event that broke and a side-by-side of what was expected vs what got produced.
you can replay yesterday's production runs through today's changed code (depending on the change ofc) and now you have a regression test suite built out of real traffic.
a very niche use which most apps of today probably wouldn't need but now it's something that exists and i built it.
ok but how
for replays to work today's code has to regenerate the same events the recording has. and that's where it gets annoying, because half the stuff your code does isn't deterministic.
time.Now() returns different values every call. rand.Intn() is the entire point of rand.Intn(). an HTTP call returns whatever the world feels like.
every one of these is a place where replay can diverge for reasons that have nothing to do with your code being wrong.
so starling wraps them. you don't call time.Now(), you call step.Now(). you don't call rand.Intn(), you call step.Random(). anything more open-ended (a payment API, a database write, a third-party HTTP call) goes through step.SideEffect(). each wrapper runs the underlying call the first time and records the result as a SideEffectRecorded event. on replay, the wrapper returns the recorded value instead of running the call again.
so yeah, working with starling means you have write your code slightly differently now. in practice this doesn't change any of your business logic but it still can be a pain in the ass but that's the price you pay for getting a recording you can actually do something with.
dealing with slow reads (CQRS)
reading by walking through the entire event log every time is stupid, if you wanna query something like how many hit budget this month, you'd be folding millions of events on every request.
the simple fix to this problem is to split the read path from the write path. all the reads go to projections, which are denormalised tables computed from the event log.
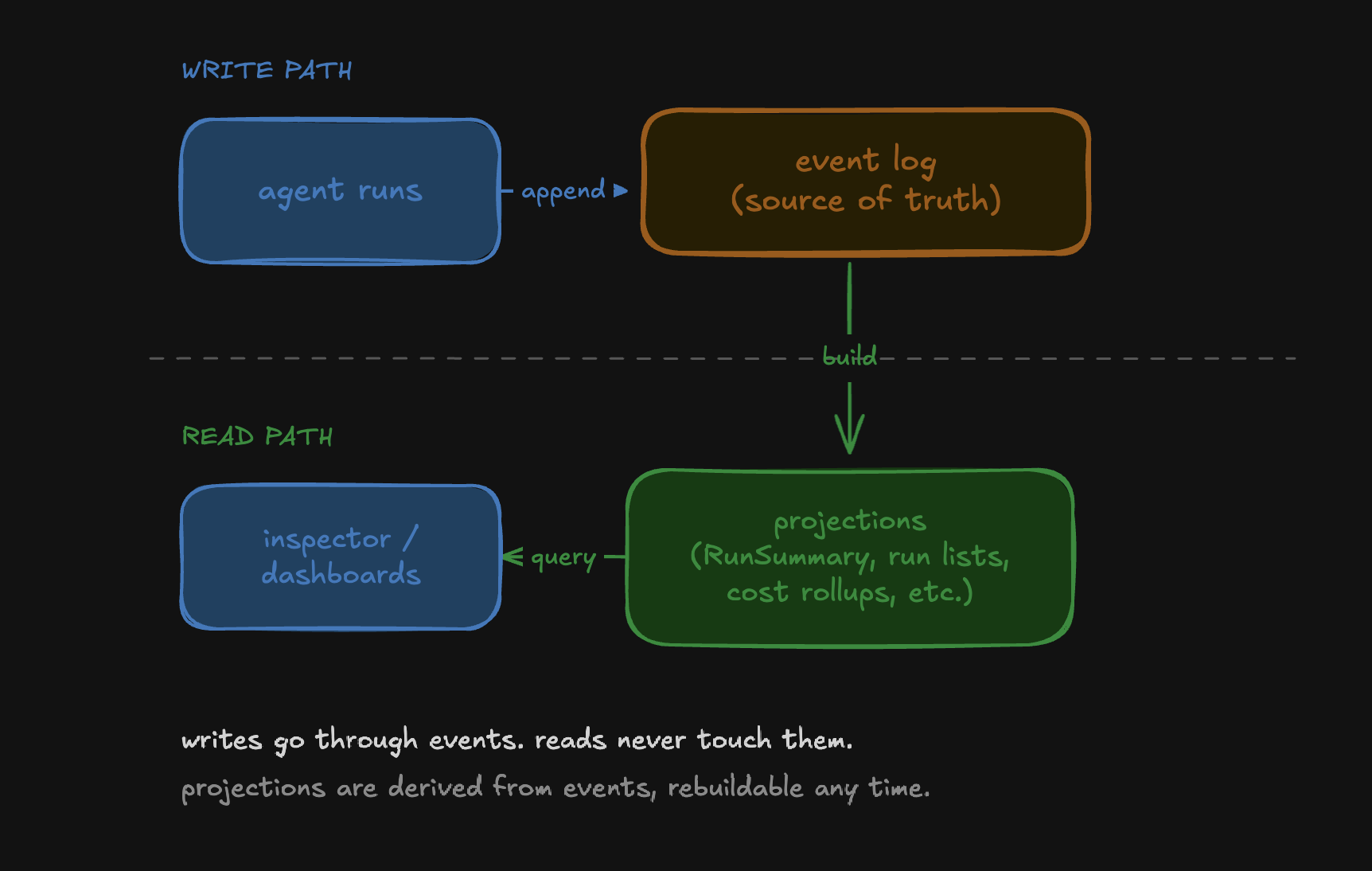
starling already does this. RunSummary is a projection, one row per run with the totals (cost, duration, turn count, hit_budget) computed once when the run completes. the inspector's runs list queries this table, not the events.
the events are still the source of truth. if a projection ever drifts or a new view is needed, you rebuild it by walking the events once since the events were never the read path.
i want you to build with starling
this post has been about event-sourcing cause that's the coolest part about starling, but that's not what starling is about.
what i have built is just a really robust agent SDK for Go.
you can use it without caring about replay, audit, or any of the cryptography. it's still a clean, batteries-included framework for shipping production agents in a Go codebase.
the thing i'm pleased with is how little there is, intentionally keeping it just to the bare minimum for people who want to plug something in their go project and get started with agents with the least overhead asap. one binary. one database (postgres or sqlite).
multiple providers, the inspector is a single Go binary, dependency-free Go templates and HTMX, opens the database read-only at the storage layer so you literally cannot edit a run by accident.
there's also a CLI for the boring stuff.
i have put quite a lot of time in the docs website, everything you and your agent needs to build with starling is out there.
byee
i built this thing to be actually used by people and not just something which sits around as a sexy project in my resume. i urge you to go check the thing out and just keep it in the back of your mind and if any of you go devs need to do some ai stuff in your projects in the future, you'll know exactly where to look. given i don't abandon maintaining the project by then.
thanks for reading. see ya :)
If you found this write-up useful, feel free to fund my caffeine addiction: